Spellchecker¶
This nbextension provides a CodeMirror overlay mode to highlight incorrectly spelled words in Markdown and Raw cells:
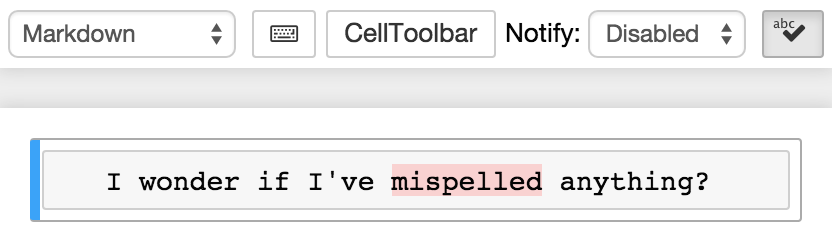
It was inspired in part by sparksuite/codemirror-spell-checker at the suggestion of @jankatins.
Spellchecking¶
The actual spellchecking is performed by the Typo.js library, which is included as a dependency, with its own license. Typo.js allows the use of hunspell-style dictionaries in a javascript-based spellchecker.
Dictionaries¶
The dictionaries used by the nbextension are fetched according to the
parameters stored in config. To keep this repository lightweight, no
dictionaries are incuded, and by default the nbextension fetches an en_US
dictionary from the jsdelivr.net cdn.
However, you can also add your own dictionaries for other languages, or to
remove dependency on the cdn (and thus make the nbextension usable offline).
To use your own dictionary, you’ll need to alter the .aff and .dic urls in
the nbextension’s config.
The urls can be relative (for files on your jupyter server) or absolute (for
files hosted elsewhere, e.g. on a cdn, like the defaults).
This is probably easiest to understand with some explicit examples.
Let’s say I want to install a de_DE dictionary.
I can get the hunspell files from anywhere I like, but in this example I’m
going to download copies of the ones listed in the
chromium source distribution,
which includes quite a lot of different languages.
I place my downloaded dictionary .aff and .dic files inside the
nbextension in the jupyter data directory, such that the directory structure
looks like the following:
spellchecker/
README.md
config.yaml
main.css
main.js
screenshot.png
typo/
LICENSE.txt
typo.js
dictionaries/
de_DE.aff
de_DE.dic
Then, I need to set the urls in the config to give the location of the
dictinaries relative to the spellchecker/main.js file and starting with ./.
So, in this case, I would use ./typo/dictionaries/de_DE.aff and
./typo/dictionaries/de_DE.dic.
To install the dictionaries into the per-user jupyter_data_dir(), you can use
the following python snippet with the appropriate language code to fetch and
save the appropriate files, and configure the nbextension to use the
newly-installed language:
from __future__ import print_function
import base64
import os.path
from jupyter_core.paths import jupyter_data_dir
from notebook.services.config import ConfigManager
try:
from urllib.request import urlopen # Py3
except ImportError:
from urllib import urlopen # Py2
remote_base_url = (
'https://chromium.googlesource.com/' +
'chromium/deps/hunspell_dictionaries/+/master'
)
local_base_url = os.path.join(
jupyter_data_dir(),
'nbextensions', 'spellchecker', 'typo', 'dictionaries')
lang_code = 'de_DE'
if not os.path.exists(local_base_url):
print('creating directory {!r}'.format(local_base_url))
os.makedirs(os.path.realpath(local_base_url))
cm = ConfigManager()
for ext in ('dic', 'aff'):
dict_fname = lang_code + '.' + ext
remote_path = remote_base_url + '/' + dict_fname + '?format=TEXT'
local_path = os.path.join(local_base_url, dict_fname)
print('saving {!r}\n to {!r}'.format(remote_path, local_path))
with open(local_path, 'wb') as loc_file:
base64.decode(urlopen(remote_path), loc_file)
rel_path = './typo/dictionaries/' + dict_fname
cm.update('notebook', {'spellchecker': {ext + '_url': rel_path}})
cm.update('notebook', {'spellchecker': {'lang_code': lang_code}})
The above is also included as part of the nbextension, and should be available here.
Internals¶
Any mispelled word has the css class cm-spell-error applied to it, so you can
customize their styling in your custom.css file if you’d like.